优化查询
支持前缀搜索
我们简单测试我们的查询,会发现查询还是有些问题,比如看一下下面的一个查询,我们搜索 Elastic,可以看到返回了一些结果:
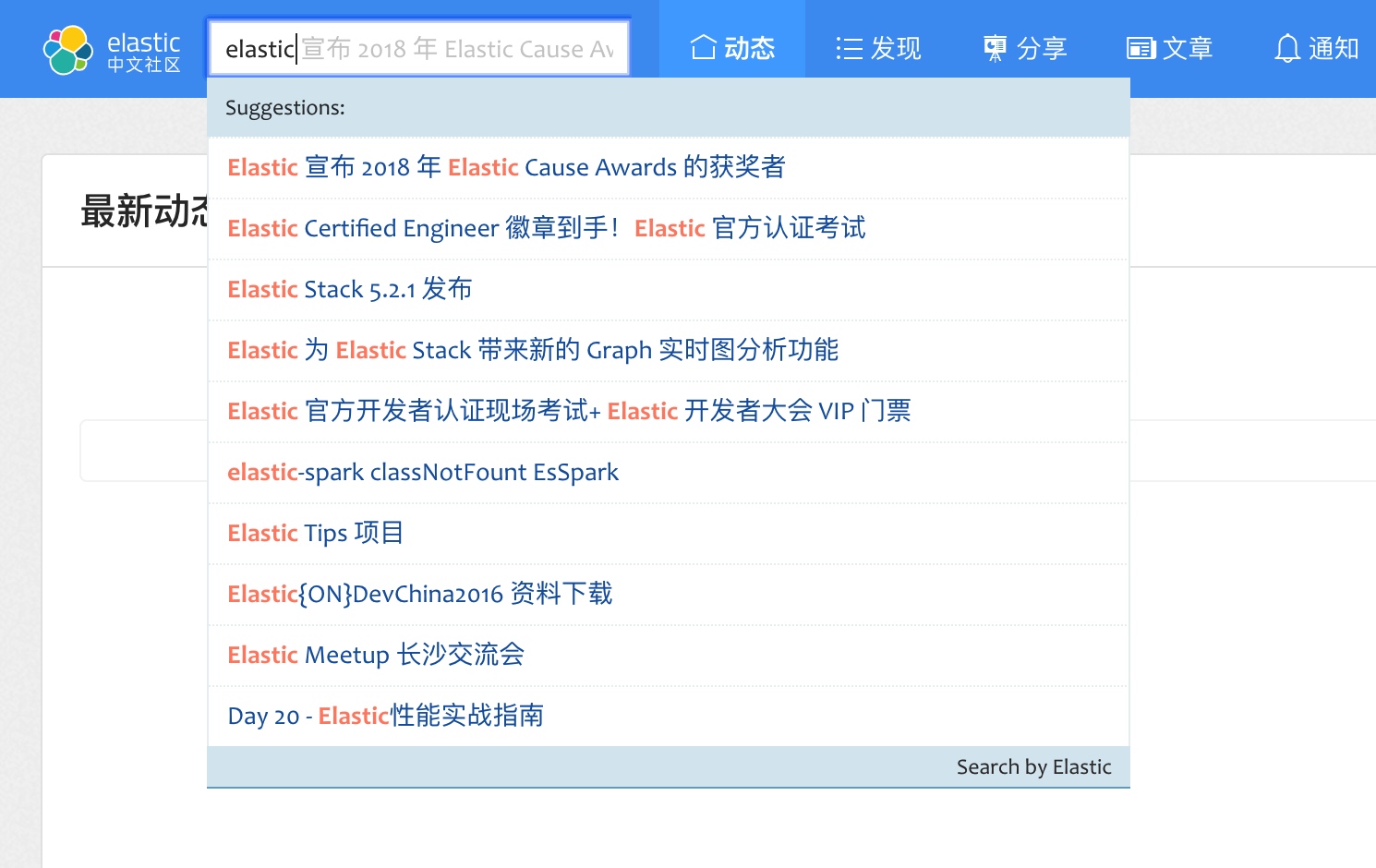
但是在我们正确输入正确的词语之前,比如我们输入的是 Elas,则什么也找不到,如下:
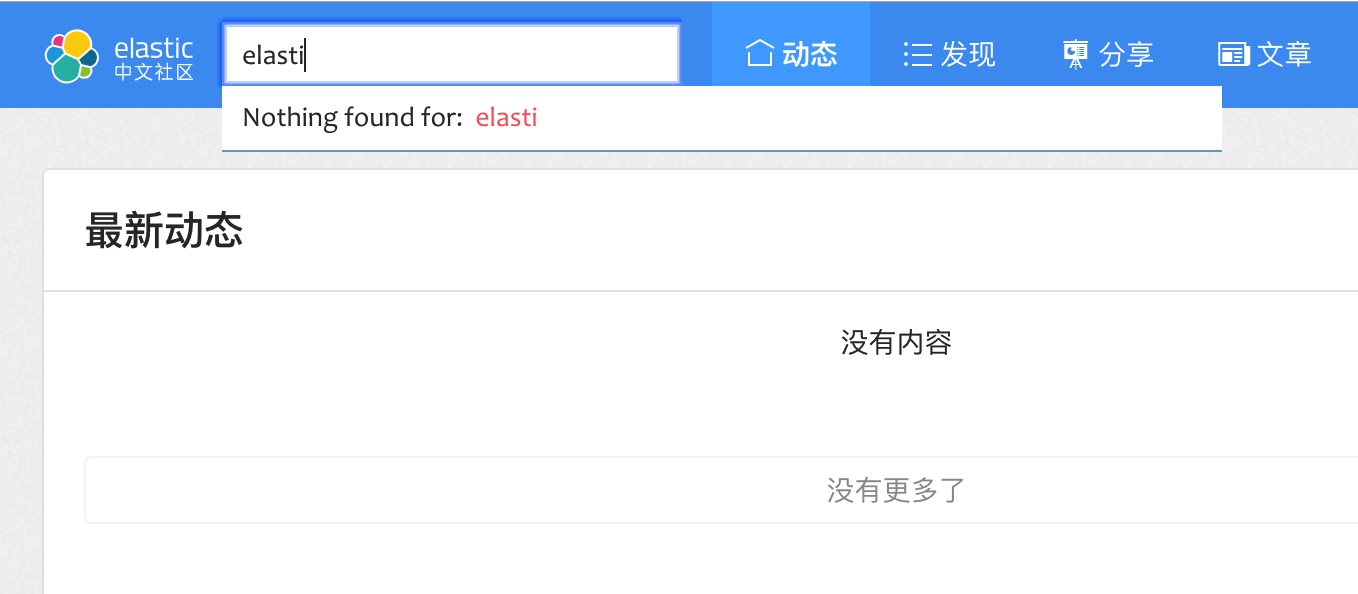
恩,这个问题就是我们第一个要优化的问题。 我们现在已经使用了模板来管理我们的查询了,所以我们替换后端的查询变得非常简单,在我们实际的动手修改模板定义的查询之前,我们可以先直接在 Kibana 里面调试好我们的查询,更方便和高效。
到目前为止,我们的查询使用的是简单的 Match 查询,Match 查询时候简单的文本匹配,那怎么实现一个前缀匹配,答案就是 Prefix 查询,我们尝试如下的查询:
GET forum-mysql/_search
{
"query": {
"prefix": {
"title": {
"value": "elas"
}
}
},"_source": "title"
}
前几条结果分别为:
- Day 20 - Elastic性能实战指南
- Day 13 - Elasticsearch-Hadoop打通Elasticsearch和Hadoop
- …
- Elastic日报 第473期 (2018-12-09)
可以看到,Prefix 查询生效了,能够通过部分字母查到完整的数据,但是前面几条数据貌似有点奇怪,比如第一条,开头的数据不是 Elas,而是 Day 20,为什么会这样呢?明明使用的是 prefix 查询啊?
答案就在我们所使用的字段是 title 字段,title 字段是 text 的类型,也就是会应用文本分析器将原始的字符串拆分成了若干个词语,而我们这里的 prefix 查询是对词语级别进行的前缀匹配,而如果一个字段拆分之后,就变成了若干个词语,所以在查询的时候,其实每个词语都是平等的,都会进行一个前缀匹配,任意词语匹配上查询都算这个字段匹配上这个查询,而不会管这些词语原始的字符串的顺序。
所以,我们不能使用分词的字段来使用 prefix 查询,我们可以使用 title.keyword 这个字段,这个字段是不分词的。修改之后的查询如下:
GET forum-mysql/_search
{
"query": {
"prefix": {
"title.keyword": {
"value": "elas"
}
}
},"_source": "title"
}
重新查询得到的结果如下:
- elasticsearch优秀实践
- elasticsearch-官网中文文档
- …
不错哈,前缀搜索的问题解决了。
查询的组合
但是,我们如果执行普通的文本查询怎么办,比如搜索 Elasticsearch SQL,结果却搜索不出来了,这个不妙,总不能捡了芝麻丢了西瓜啊,有没有办法同时支持这两种查询呢?
答案就是使用 Bool 查询,在 Elasticsearch 内部有多种类型的查询,其中有一些查询类型是用来组合其他查询的,示例如下:
GET forum-mysql/_search
{
"query": {
"bool": {
"should": [
{
"prefix": {
"title.keyword": {
"value": "Elasticsearch SQL"
}
}
},
{
"match": {
"title": {
"query": "Elasticsearch SQL"
}
}
}
]
}
},
"_source": "title"
}
权重控制
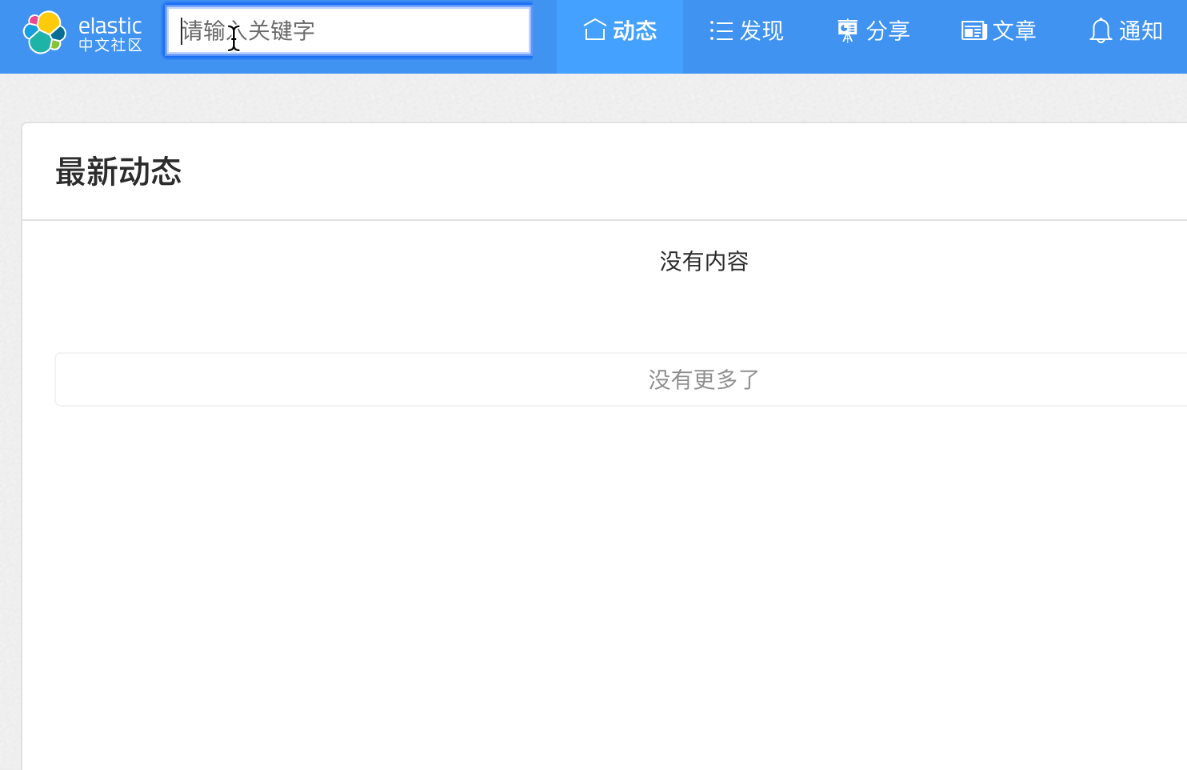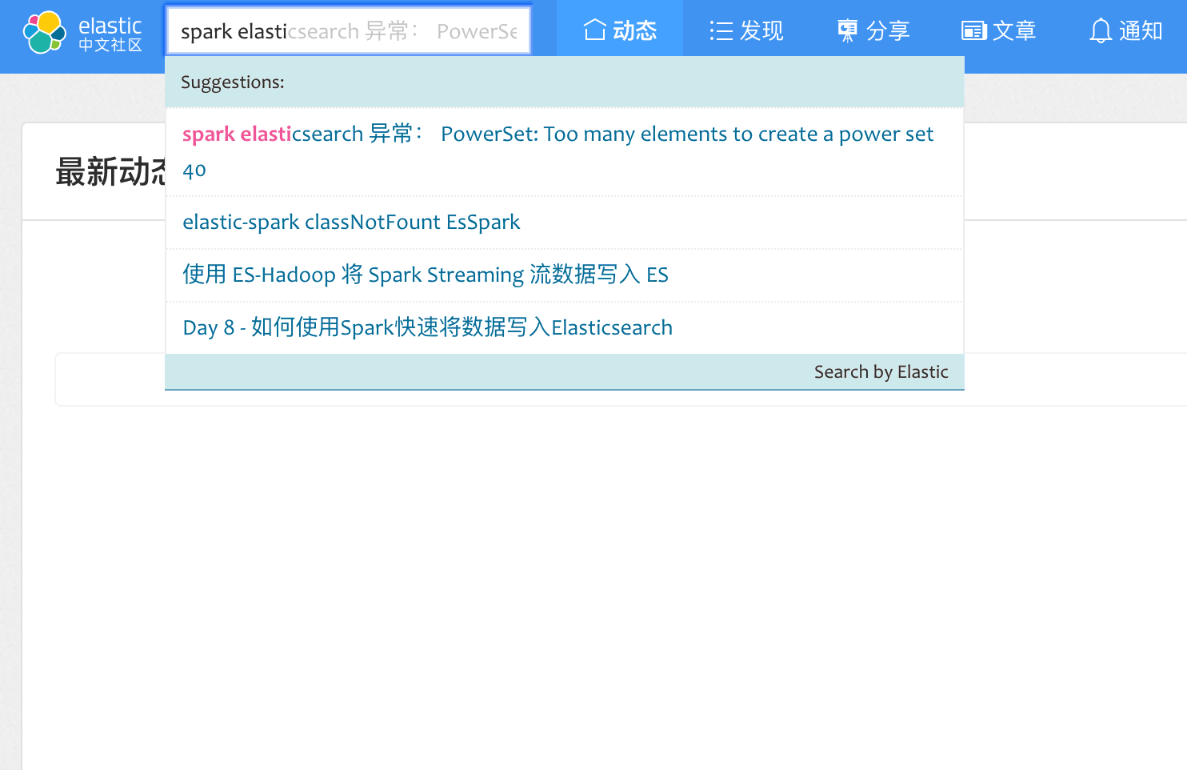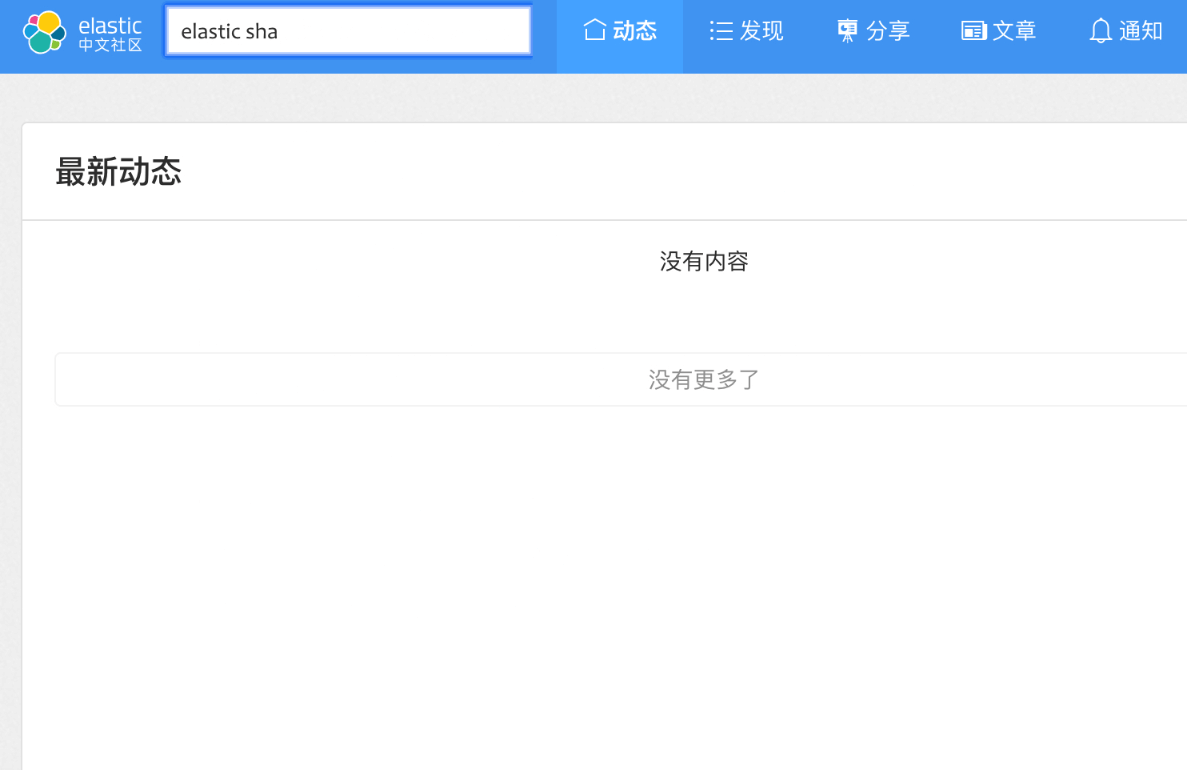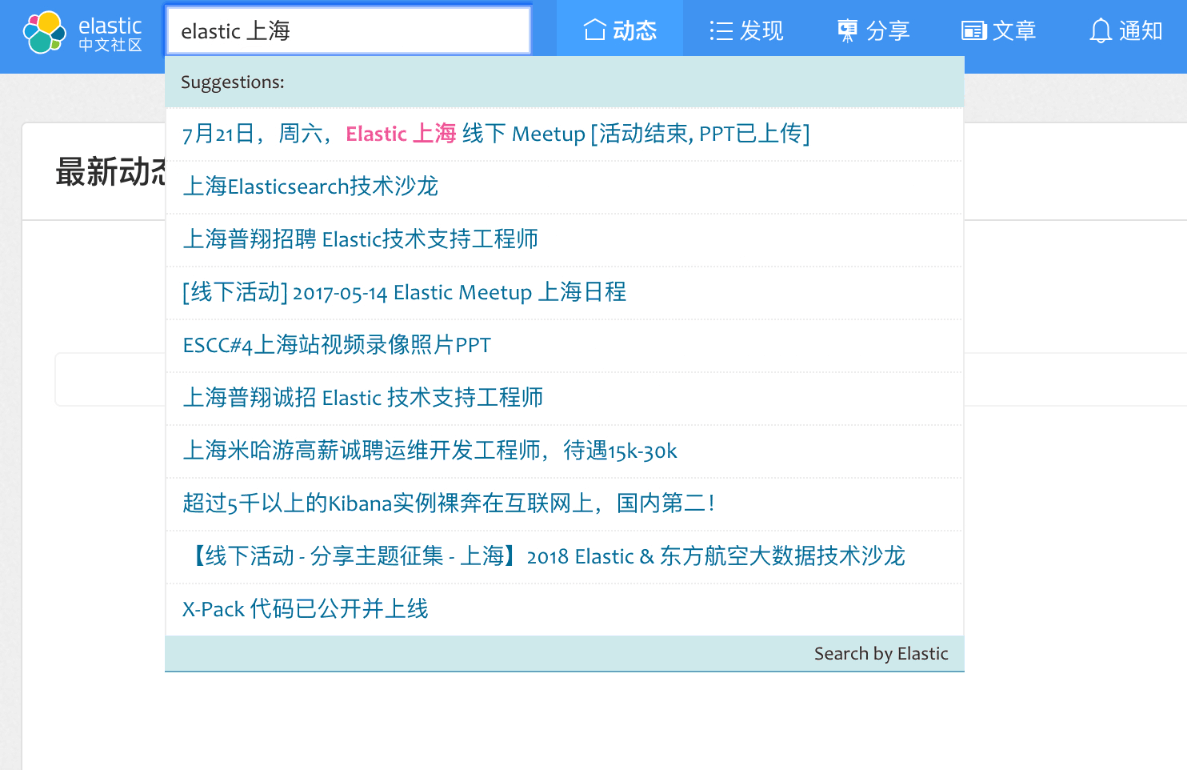
为了保证查询的效果,我们对上面的查询关键字换另外查询试试看,换成的 spark 的结果共有5条,分别是:
- elastic-spark classNotFount EsSpark
- spark elasticsearch 异常: PowerSet: Too many elements to create a power set 40
- 使用 ES-Hadoop 将 Spark Streaming 流数据写入 ES
- 如何使用Spark快速将数据写入Elasticsearch
- spark1.6.3+elasticsearch5.4 netty jar冲突
而关键字 spar 的结果却只有2条,分别是:
- spark elasticsearch 异常: PowerSet: Too many elements to create a power set 40
- spark1.6.3+elasticsearch5.4 netty jar冲突
通过这两个查询,我们又发现了两个问题:
spark名字了5条结果,说明5篇文章的标题匹配了 spark 关键字,但是排第二和第四的文档标题按理要排在靠前的文章,因为他们是 spark 开头的。spar作为前缀匹配命中了2条结果,准确率效果不错,但是太严格了,还有一些和 spark 相关的,但是不是开头的文章没有找出来,假如文档都不是 spark 开头,那就会出现找不到,我们可以优先 spark 开头的在前面,不过也应该容忍出现在其他的位置,尤其是 spark 作为开头的位置没有的情况下。
我们的 bool 查询其实在 should 里面组合了两个子条件,这两个子条件是平等的关系,任意满足即可将命中返回,但是其实我们是希望这些查询有一些偏好倾向的,对应这样的两种问题,我们可以通过设置boost 权重来控制这些子条件命中结果的命中得分来调整最后返回结果的顺序。修改过后的查询如下:
GET forum-mysql/_search
{
"query": {
"bool": {
"must": [],
"should": [
{
"prefix": {
"title.keyword": {
"value": "spark",
"boost": 10
}
}
},
{
"match": {
"title": "spark"
}
}
]
}
},
"_source": "title"
}
现在我们的查询结果是这样的:
- spark elasticsearch 异常: PowerSet: Too many elements to create a power set 40
- spark1.6.3+elasticsearch5.4 netty jar冲突
- elastic-spark classNotFount EsSpark
- 使用 ES-Hadoop 将 Spark Streaming 流数据写入 ES
- Day 8 - 如何使用Spark快速将数据写入Elasticsearch
太棒了! 是不是正如和我们预期的一样。
Phrase 查询
我们继续测试,我们比如换这个查询 elastic 上海,得到的查询结果如下:
- 上海Elasticsearch技术沙龙
- 上海普翔招聘 Elastic技术支持工程师
- [线下活动] 2017-05-14 Elastic Meetup 上海日程
- ESCC#4上海站视频录像照片PPT
- 7月21日,周六,Elastic 上海 线下 Meetup [活动结束, PPT已上传]
- …
通过对结果的观察,我们会发现只有第五条是最符合我们查询的,但是确排在了比较靠后的位置,这又是怎么回事呢?
原来,我们的条件是一个句子,Elasticsearch 同样会在搜索的时候,对查询的关键字进行文本分析处理,将一个长句子拆分成多个词语,分别对这些词语进行倒排索引的搜索。我们可以看看这个用来测试分析结果的例子:
GET forum-mysql/_analyze
{
"field": "title",
"text": ["elastic 上海"]
}
我们索引的这个 title 字段使用的是默认的 standard analyzer,会进行简单的文本拆分,对于中文则是一个字一个字的拆分,所以我们查询条件分析的结果如下:
{
"tokens" : [
{
"token" : "elastic",
"start_offset" : 0,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "上",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "海",
"start_offset" : 9,
"end_offset" : 10,
"type" : "<IDEOGRAPHIC>",
"position" : 2
}
]
}
在我们测试的查询中,第一个通过关键字的 prefix 前缀匹配应该是没有任何命中数据的,而第二个match 查询则分别通过这四个关键字:elastic、上、海 在索引里面进行倒排索引的匹配。所以出现这些结果也就不足为奇了。
但是,问题就出在这里,这些关键字在处理的时候,是并列关系,但是我们其实在输入关键字的时候,其实是希望这句条件是有先后顺序的,也就是我们希望的应该是 elastic 上海 优先于 上海 elastic 的,那怎么办呢?
答案就是使用 match_phrase 查询,match_phrase 查询就是这么一个存在,相比 match 查询多了一个词语位置关系的处理,既然如此,我们添加一个 match_phrase 查询,并权重比 match 查询要高,同时比 prefer 查询低,如下:
GET forum-mysql/_search
{
"size": 5,
"query": {
"bool": {
"must": [],
"should": [
{
"prefix": {
"title.keyword": {
"value": "elastic 上海",
"boost": 10
}
}
},
{
"match_phrase_prefix": {
"title": {
"query": "elastic 上海",
"boost": 2
}
}
},
{
"match": {
"title": "elastic 上海"
}
}
]
}
},
"_source": "title"
}
现在执行查询得到的结果就是这样:
- 7月21日,周六,Elastic 上海 线下 Meetup [活动结束, PPT已上传]
- 上海Elasticsearch技术沙龙
- 上海普翔招聘 Elastic技术支持工程师
- [线下活动] 2017-05-14 Elastic Meetup 上海日程
- ESCC#4上海站视频录像照片PPT
更新模板
经过我们多次的迭代,我们已经得到了最终的查询条件了,现在我们只需要在我们的 Elasticsearch ,更新到我们的搜索模板即可完善我们用户的搜索体验了,脚本如下:
POST _scripts/forum_search_template_v1
{
"script": {
"lang": "mustache",
"source": {
"size": "{{size}}",
"query": {
"bool": {
"must": [],
"should": [
{
"prefix": {
"{{field}}.keyword": {
"value": "{{query}}",
"boost": 10
}
}
},
{
"match_phrase_prefix": {
"{{field}}": {
"query": "{{query}}",
"boost": 2
}
}
},
{
"match": {
"{{field}}": "{{query}}"
}
}
]
}
},
"_source": [
"title",
"id",
"uid",
"views"
]
}
}
}
现在,可以打开我们的浏览器,在输入框里面,分别输入我们之前测试的查询条件做一个交叉验证。
最后,我们其实还可以开发一个辅助的测试工具,来记录我们的查询及对应的结果与查询结果所对应的顺序,每次查询修改或者优化之后,对一些典型的测试场景进行反复严重,实现一个自动化批量化的验证,很多情况下,查询条件在不同场景可能会出现冲突,我们要尽可能满足大多数场景下的查询需求。