简繁处理
我们可以看到很多的国际化站点都支持多语种的内容,而中文的支持又分为简体中文和繁体中文,对于中国大陆来说,我们主要使用的是简体中文,而港澳台则主要是繁体中文,另外还有部分使用繁体字的海外华人。且香港和台湾两个地区对于繁体的使用又有一些区别,这和每个地区的用户习惯密不可分,Elastic 中文社区覆盖的用户是所有的中文用户,自然要考虑到所有和中文相关的需求,而简繁体的检索支持就是一个非常重要的功能。
这一节我们主要讲讲如何来实现简繁体的搜索。
汉字的历史
中国文化博大精深,从文字可见一斑,目前最早可查的是甲骨文,古时候没有纸笔,聪明的古人为了记录一些重要的事情,发明了象形文字刻画在动物的甲壳或者动物骨头上,后面又演变为刻在金属器皿上的金文,再到篆书、隶书、楷书等等,这一路走来,我们会发现人类的科学水平越来越提高,从骨头到金属再到纸张,并且文字的影响范围越来越大,文言文为什么这样晦涩难懂,惜字如金,我觉得一个是古时候书写材料和传播的成本比较高昂,只能想办法高度概括和惜字如金,作为对比,大家看如今的互联网的传播时代,大家对于文字的使用简直是十分随意,也完全不在乎语法,各种网络用语横空出世,相信大家也都见怪不怪了。
小知识
以下内容来自 百度百科
繁体字,也称繁体中文,欧美各国称之为传统中文(Traditional Chinese),一般是指汉字简化运动被简化字所代替的汉字,有时也指汉字简化运动之前的整个汉字楷书、隶书书写系统。繁体中文至今已有三千年以上的历史,直到1956年前一直是各地华人中通用的中文的标准字。
近代成规模的汉字简化运动,最早在太平天国,简化字主要来源于历朝历代的古字、俗体字、异体字、行书与草书的楷书化。1935年中华民国国民政府教育部颁布《第一批简体字表》,但因考试院院长戴季陶反对而搁置。1956年1月28日,中华人民共和国国务院发布《关于公布〈汉字简化方案〉的决议》,中国大陆开始全面推行简化字,20世纪70年代曾经有过一批二简字,后被废除。
目前仍然使用繁体字的地区有中国的台湾地区、香港特别行政区和澳门特别行政区,汉字文化圈诸国,新加坡以及马来西亚等海外华人社区多为繁简体并存,中国内地在文物古迹、姓氏异体字、书法篆刻、手书题词、特殊需要等情况下保留或使用繁体字。
2001年1月《中华人民共和国国家通用语言文字法》实施,明确规定中国推行规范汉字,同时也明确保留或使用繁体字的范围。2013年6月5日中国国务院公布《通用规范汉字表》,含附表《规范字与繁体字、异体字对照表》,一般应用领域的汉字使用以规范字表为准。
简体和繁体之间
台湾人管鼠标叫滑鼠,磁盘叫硬碟,而香港呢,磁盘却叫磁碟,连英文的翻译习惯也不一样,人名 George 我们一般翻译成乔治,而香港翻译成佐治,再比如兰博基尼与林宝坚尼,奔驰与平治,同样是繁体字,台湾人说国语也就是普通话,香港澳门却说广东话,这两地方的广东话还不完全一样,哎,这些文化差异,真是想想都头大。
所有,我们可以总结一下简体和繁体的几个主要情况:
- 字形差异,汉字字形本身存在着明显差异,如劉与刘,一般是单个字。
- 词汇的差异,习惯、文化环境造成的用法差异,如滑鼠与鼠标,一般是多字词语。
- 多种形态共存,有很多代表不同意思的繁体最后简化成了一个字,所以就出现了多音和多义的简体字,如:飆、飈、𩙪都对应于一个简体:飚。
对应第一种,我们可以采用替换的办法,将所有的繁体都替换成对应的简体,在创建索引的时候,就进行标准化,比较好实现,第二种我们可以采用收集相应的词汇转换关系,进行替换,不过因为是多字词语的替换,所以这里面还需要提取处理好分词,不然就有可能替换错误反而引起歧义的问题。而对于第三种情况,因为繁体和简体是一对多的情况,我们将繁体通过映射表转成简体相对容易,反过来将简体转换成繁体将遇到调整,可能需要结合前后语义来选择正确的繁体。
繁体转简体
回到我们的任务,我们的社区网站以简体内容为主,那偶尔出现的繁体查询条件或者在问题或者文章评论里的繁体的文字,我们如果都统一转换成简体,所有的问题也就迎刃而解了。看来不管做什么,只要我们明确我们的需求,缩小我们的范围边界,事情就好办多了。
简繁体转换插件
工欲善其事必先利其器,必先利其器,关于繁体转换,我很早以前写过一个插件,这里就给大家介绍一下怎么使用。
这个插件在 Github 上的地址是: https://github.com/medcl/elasticsearch-analysis-stconvert,我们前往 release 页,根据当前使用的 Elasticsearch 的版本,下载一个对应的 zip 格式的插件包,如下图:
Elasticsearch 的插件的安装也非常简单,通过 Elasticsearch 安装程序目录 bin 下面的插件命令 elasticsearch-plugin 就可以直接安装,格式如下:
./bin/elasticsearch-plugin install <插件包的 URL 地址或者本地路径>
安装完成之后,在 Elasticsearch 的 plugin 目录就能看的一个子目录 analysis-stconvert,也就是我们插件所在的地方,如下:
 其实我们不用命令行的方式安装,直接自己从网站上下载对应的插件包,手动解压到 plugins 下面的一个子目录下面,目录名称可以随意,完全可以达到相同的安装效果。
其实我们不用命令行的方式安装,直接自己从网站上下载对应的插件包,手动解压到 plugins 下面的一个子目录下面,目录名称可以随意,完全可以达到相同的安装效果。
最后,Elasticsearch 的所有的插件,在安装完毕之后,都需要重启之后才能生效。
小知识
- Elasticsearch 插件安装需要下载对应的版本,可以使用手动解压到 plugins 子目录的方法进行安装。
- 使用插件命令安装,可以指定插件的 ZIP 包的 URL 地址,或是本地路径,本地路径要注意格式,如
file:///路径/文件名。 - 插件安装完毕,需要重启 Elasticsearch 才能生效。
验证安装
安装并重启完了,那如何验证我们的 Elasticsearch 是否真的安装成功了呢,首先,我们可以通过访问 _cat/plugins 接口来查看当前集群里面正常安装的插件列表,看看有没有我们的插件,如下:

可以看到,_cat/plugins 接口返回了一个列表,其中就有我们的插件,以及显示了正确的版本号。
Elasticsearch 提供了一系列 由 _cat 开头的 API,可以看到它返回的不是 JSON 格式,而是非常适合在命令行下查看的表格形式,非常精简,这样对于我们的运维人员来说其实非常方便,我们只需要在命令行下就能拿到所有的信息,而不用去打开 Kibana 或者是手动构造 JSON 或是在冗长的 JSON 结果里面去查看。
另外,如果你的集群里面有不止一个 Elasticsearch 的节点,你需要在每一台 Elasticsearch 的实例上执行相同的插件安装,并进行重启让其加载生效。
插件介绍
STConvert 这个插件一共提供了 4 个不同的组件:
- 一个名为
stconvert的 Analyzer,可以将简体转换成繁体 - 一个名为
stconvert的 Tokenizer,可以将简体转换成繁体 - 一个名为
stconvert的 Token Filter,可以将简体转换成繁体 - 一个名为
stconvert的 Char Filter,可以将简体转换成繁体
每个组件都可以有以下3个参数用来进行自定义配置,分别是:
- 参数
convert_type设置转换的方向,默认是s2t,表示简体到繁体,如果要将繁体转换为简体,则设置为t2s - 参数
keep_both用于设置是否保留转换之前的内容,一般来说保留原始内容可以提高我们的搜索命中率,默认是false,也就是不保留 - 参数
delimiter主要是用于,当保留原始内容的时候,如何分割两部分内容,默认的值是逗号,
Analyzer 介绍
这些组件都是什么呢,还是让我先来给你简单介绍一下关于 Analyzer 的一些基本知识吧,在 Elasticsearch 里面,一个 Analyzer 有 3 个主要的部件组成,分别是:Char Filter、Tokenizer、Token Filter,一个 Analyzer 有且必须有一个 Tokenizer,可以有0到多个 Char Filter 和 Token Filter。
[Analyzer]: (0..n)[Char Filter]->(1)[Tokenizer]->(0..n)[TokenFilter] 【待画图】
我们以 Standard Analyzer 来说明他们的工作原理吧,一个 Standard Analyzer 由一个 StandardTokenizer 以及 StandardFilter、LowerCaseFilter和 StopFilter(默认未启用) 组成,如下图所示:
StandardTokenizer 的分词算法基于 Unicode 的词语规则,对于英语等基于空格的语种,会采用空格进行切分成单词,而对于中文,则只能按单个字单个字进行拆分。
对应这样的一个文本:我爱 China。,我们使用 standard Analyzer 来进行分析,我们看一下他的分析流程:
- 先使用 Standard Tokenizer,进行分词,分词结果为:
我、爱、China,可以看到这里移除了一些标点符号和空格 - 然后上一个分词的结果会分别使用 LowerCaseFilter 来进行处理,也就是转换成小写
- 如果配置了停用词,则会对上一次过滤的每个词,分别应用停用词过滤规则
我们也可以通过 _analyze 来手动测试一下 standard 这个 Analyzer 的分词结果,测试方法如下:
GET /_analyze
{
"text": ["我爱China。"],
"analyzer": "standard"
}
得到的分析输出结果如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
从上面我们可以看到分词的每一个 Token 的位置、类型信息,对于我们调试分词效果非常有帮助。
除了调试 Analyzer,我们还能单独测试 tokenizer,如下:
GET /_analyze
{
"text": ["我爱China。"],
"tokenizer": "standard"
}
自定义分析器
既然,我们知道了一个分析器是由3部分组成的,Elasticsearch 也内置了很多的 Analyzer,假如内置的 Analyzer 满足不了我们的需求,我们是不是需要写插件才能扩展分析器呢,其实不用,我们可以动态的对现有的这几个组件进行组合从而动态的构建新的 Analyzer。
首先,我们看看 _analyze 如何动态的测试一个假想的 Analyzer 吧,如下:
GET /_analyze
{
"tokenizer" : "standard",
"filter" : ["lowercase"],
"char_filter" : ["stconvert"],
"text" : "我愛China。"
}
可以看到,上面的请求,我们指定了 Tokenizer 为 standard,也指定了 lowercase 作为分词之后的 Filter,这样就跟标准的 Standard Analyzer 的分析效果一样了,我们还新增了一个 Char Filter 的参数设置,使用的是我们新安装的简繁体转换插件提供的 stconvert,也就是将简体转成繁体,那对应这个文本,我们的分词结果是什么呢?我们来看看:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "愛",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
可以看到,除了和 Standard 分词效果一样的地方以外,我们还额外的将中文字符都转成了繁体,爱 字转成了 愛,而 我 没有变化,是因为它的繁体也是 我。建议我们在真正动手进行自定义分词之前,通过这样的方式先进行分词效果的测试,得到满意的结果之后再进行具体的自定义 Analyzer 的创建工作。
不过,我们看着上面的分析结果,陷入了深深的沉思,我们的需求,不是要将所有的中文字符都统一成简体的呀,可这都转成繁体了啊,这可不行啊。可是 STConvert 插件默认的行为就是繁体转简体,那有没有办法自定义,不是支持好几个自定义参数呢?
不用担心,我们在自定义 Analyzer 的时候,对现有的基本组件,如一个 tokenizer 设置属性并指定一个新的名称,这样就可以创建一个新的 tokenizer。
我们可以在创建索引的时候,在索引的 setting 里面进行配置,定义一个 analysis 节点,在该节点里面自定义设置 Tokenizer 、Token Filter 或者 CharFilter,索引的创建脚本示例如下:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["tsconvert"]
}
},
"char_filter": {
"tsconvert" : {
"type" : "stconvert",
"delimiter" : "#",
"keep_both" : false,
"convert_type" : "t2s"
}
}
}
}
}
索引创建完成了之后,我们整个索引下面就有了我们刚刚创建好的这些分析器组件的实例了,包括我们新增的 tsconvert CharFilter 以及 my_analyzer Analyzer,这个 Analyzer 使用了我们刚刚新增的 tsconvert Char Filter,并设置了相关属性,目的是将繁体转换成简体。好了,我们马上在 my_index 索引下面进行一下测试,看看我们的自定义的 Analyzer 能不能实现我们的繁体转换成简体,请求如下:
POST /my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "我愛China。"
}
经过执行,得到的分析结果如下:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "爱",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "china",
"start_offset": 2,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 2
}
]
}
可以看到,我们的繁体字符确实都转换成了简体了,太好了,我们只需要将这个同样应用到我们的社区索引不就可以标准化所有的中文数据了吗。
功能集成
到目前为止,我们还未对社区的索引做过任何的自定义,创建的索引采用的全是默认的参数,默认的参数到目前为止工作的很好,不过我们因为要修改标题字段的 Analyzer,让它都统一成简体,所以必须要对它进行修改。
索引的修改
可是怎么修改呢?索引的 Analyzer 是在索引创建的时候设置的,可是现在索引已经创建好了,也已经不能动态修改字段的 Analyzer 了。
没有办法的两种办法,第一种就是数据重建,将索引完全删除,创建一个同名的索引,创建过程中确保使用了新的索引设置,然后开始重新导入数据。不过如果数据量很多的话,会比较慢,重建过程中也会影响正常的搜索服务,第二种也是我们推荐的,创建一个新的索引,使用新的索引设置,然后将索引数据从旧索引导入到新索引,数据导入完成之后,再在程序端进行索引的选择切换。
由于我们之前完全是默认的索引配置,所以这次我们的索引创建只需要加上我们和简繁体相关的分析器配置就好了,请求如下:
PUT /forum-mysql-v1
{
"settings": {
"analysis": {
"analyzer": {
"standard_ts_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase"],
"char_filter": ["tsconvert"]
}
},
"char_filter": {
"tsconvert" : {
"type" : "stconvert",
"delimiter" : "#",
"keep_both" : false,
"convert_type" : "t2s"
}
}
}
}
}
我们设置了一个名为 standard_ts_analyzer 的 Analyzer,也把索引名带上一个版本号,方便后续的管理,现在索引创建成功了,但是还没有数据。
Mapping 修改
在导入数据之前,我们还需要做的一件非常重要的事情,就是设置字段的分析器,将标题字段的分析器设置为我们的新的支持繁体转换的分析器。
由于我们之前都是使用的动态 Mapping,我们可以先取回生成的 Mapping,然后在其基础上进行修改,这样可以节省我们构建 Mapping Json 对象的工作。取回现有 Mapping 可以使用如下的请求:
GET forum-mysql/_mapping
请求节点的 _mapping 即表示定位 forum-mysql 这个索引下面的 Mapping 信息,我们通过 GET 就能将其全部返回,返回 Mapping 结果如下:
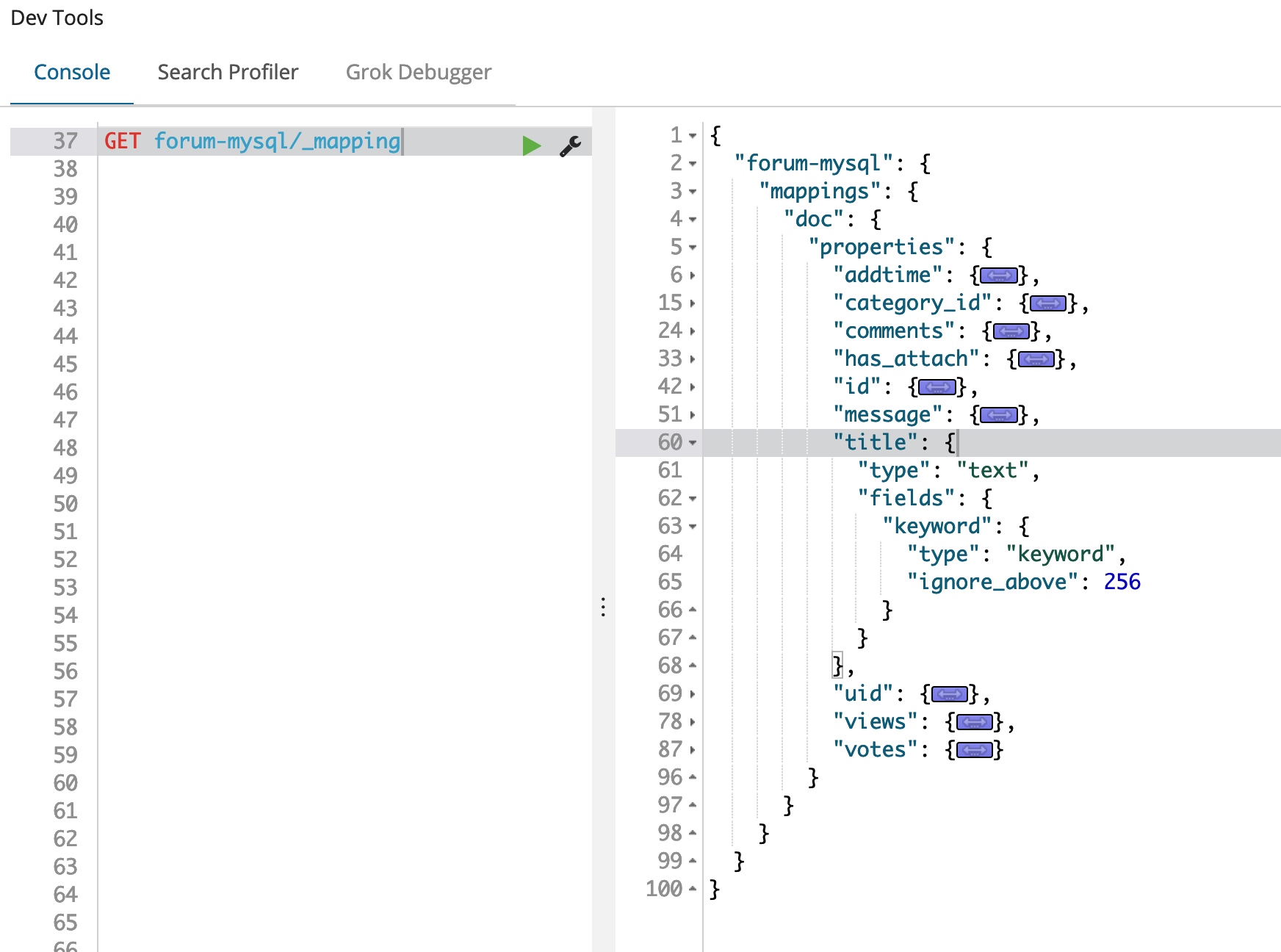
我们将返回的 Mapping 定义的 JSON 做一些修改,去除最外层的 forum-mysql.mapping.doc,只保留 properties 节点所对应的 Mapping 定义,并设置 title 和 message 字段的 Analyzer 为 standard_ts_analyzer,如下图:
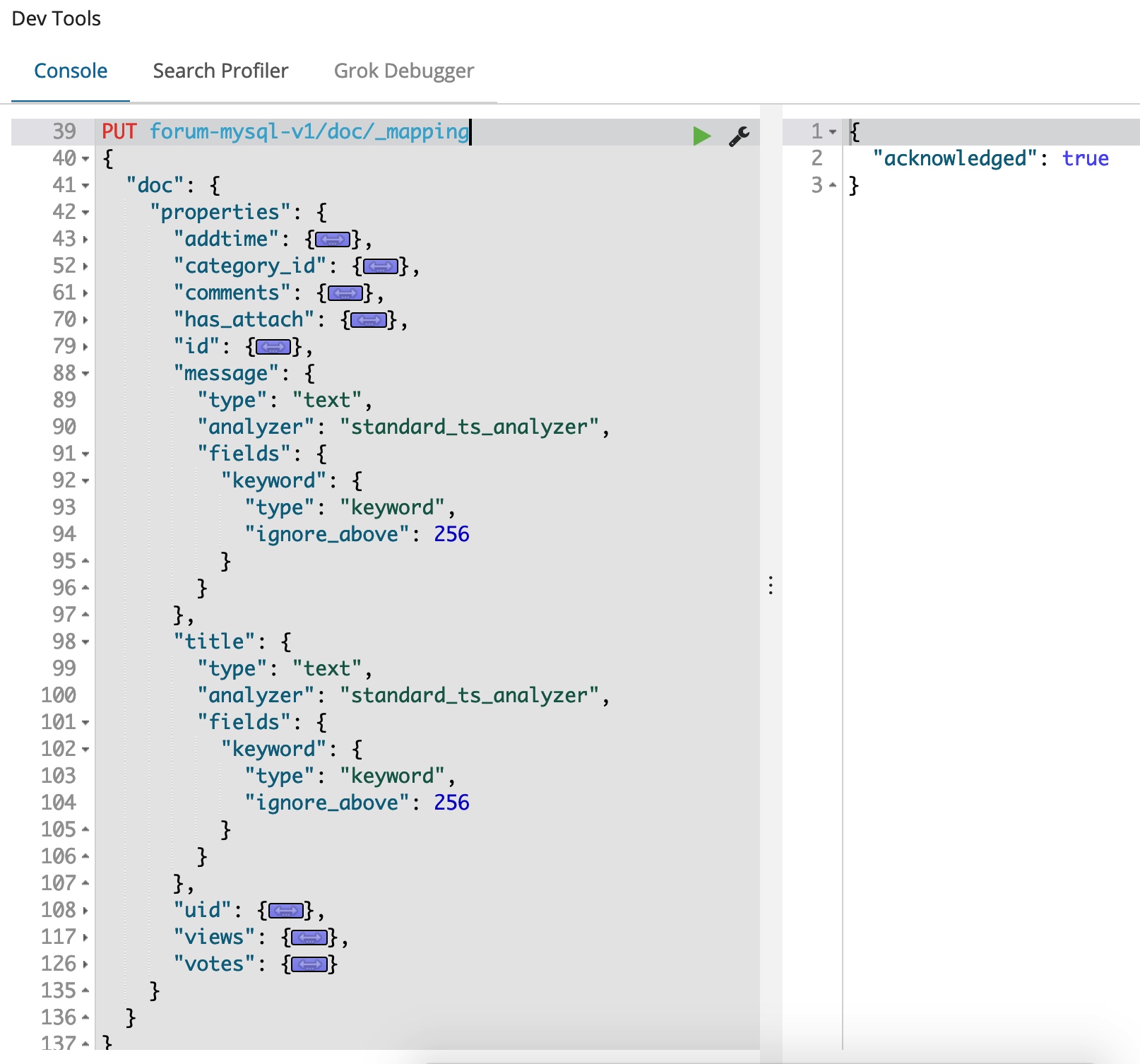
另外,我们注意到 在 title 和 message 下面的定义,有一个 fields 的定义,这个是 Elasticsearch 的 multi-fields 的概念,表示可以对一个字段通过在 Mapping 处定义不同的字段处理规则,从而实现多个虚拟子字段,从而满足不同的查询需求,每一个子字段底层都是一个单独的索引,但是在索引的时候只需要提交一个字段的数据就可以了。
我们点击执行并创建好这个 Mapping,可以看到右侧返回了执行成功的消息,现在我们的索引就已经构建好了新的 Mapping 了,下一步就是往里面导入数据了。
索引迁移
将 Elasticsearch 的数据从一个索引导入到另外一个索引,可以使用其自带的 reindex 功能,支持本集群和跨集群的数据互倒,甚至不同版本间的数据互倒,很是方便。
在我们的这个例子里,我们需要将数据从旧的 forum-mysql 索引导入到新的 forum-mysql-v1 索引,通过 reindex 导入的话,使用这一个请求就可以搞定,如下:
POST _reindex
{
"source": {"index": "forum-mysql"},
"dest": {"index": "forum-mysql-v1"}
}
导入结果如下图所示:
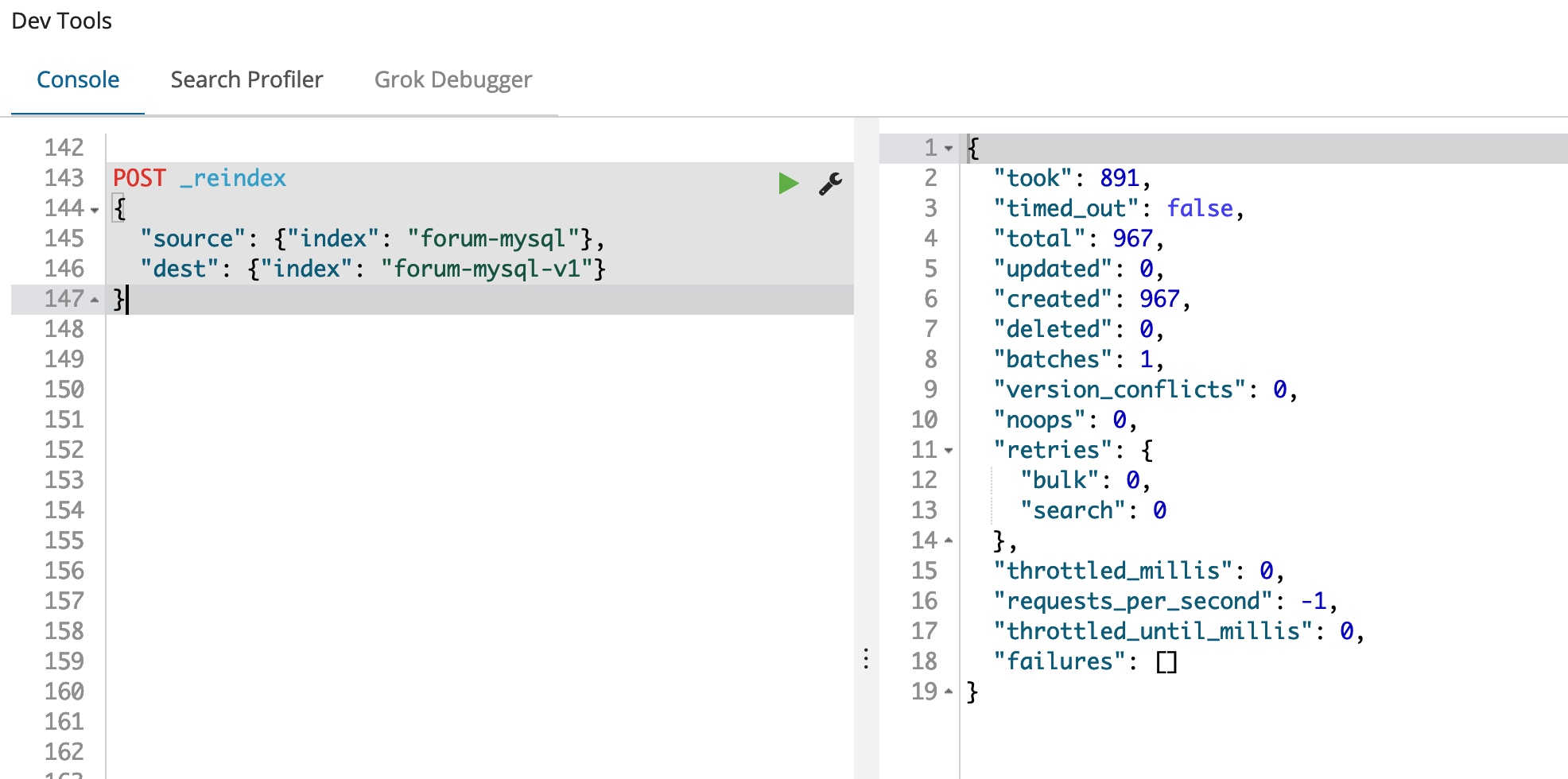
967条记录瞬间导入完成,不能再好了。
测试查询
数据也都有了,现在我们可以使用我们的查询来进行一下测试了,因为我们不知道目前索引里面都有哪些数据,我们先随便写一条语句来查询一下看看,作为对比,我们先对旧索引 forum-mysql 进行查询,如下:
GET forum-mysql/_search/template
{
"id": "forum_search_template_v1",
"params": {
"field": "title",
"query": "數據讀寫",
"size": 10
}
}
结果如下:
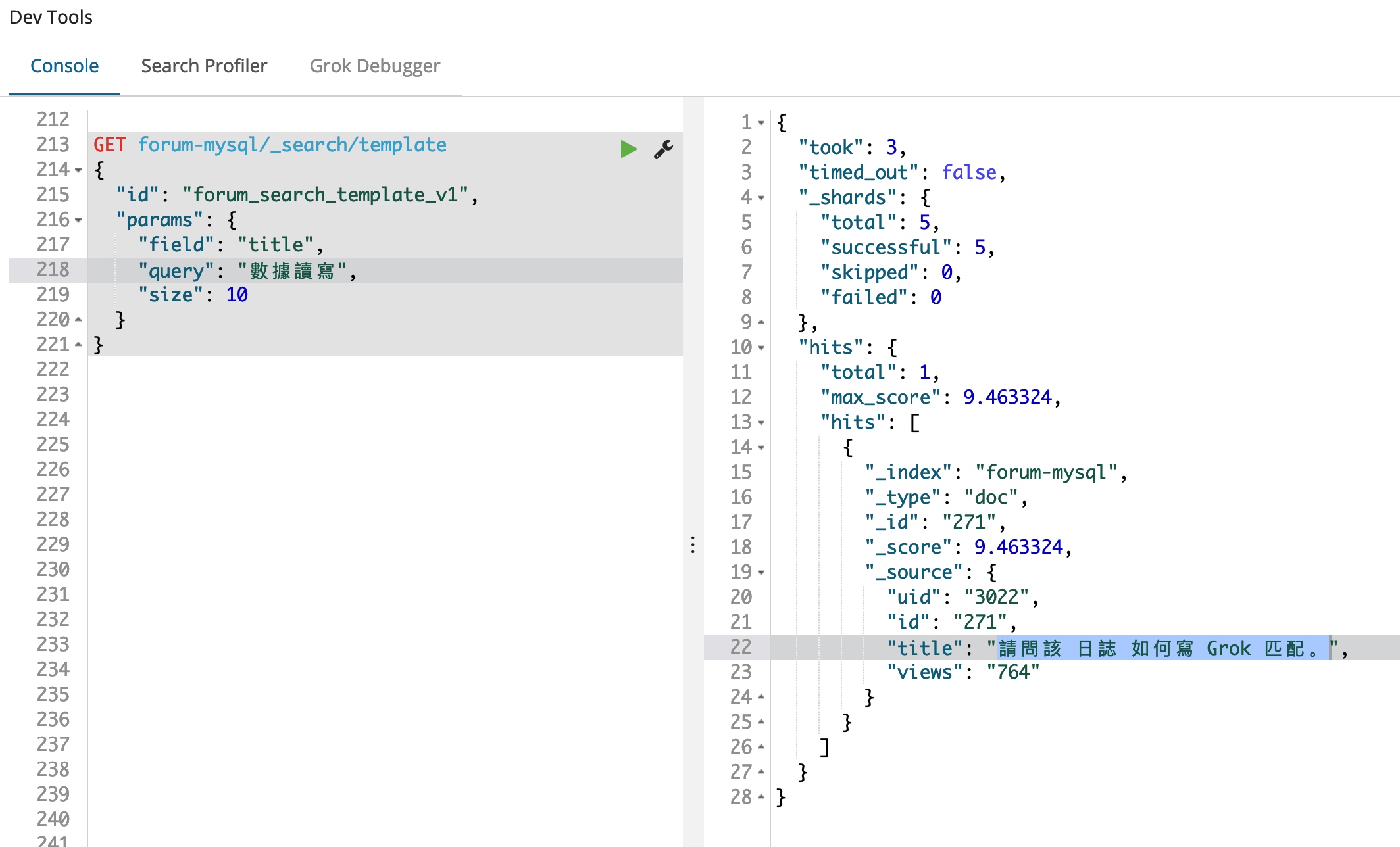 可以看到,我们的旧索引里面果然是有繁体字内容的,我们的查询条件是
可以看到,我们的旧索引里面果然是有繁体字内容的,我们的查询条件是 數據讀寫,匹配到了一条数据,并且只是通过 寫 这一个字匹配上的,从标题来看,好像有点不太相关。
那我们试试我们的新索引,因为我们使用了模板,所以,我们只需要替换一下索引名称就可以了,非常简单方便,查询条件如下:
GET forum-mysql-v1/_search/template
{
"id": "forum_search_template_v1",
"params": {
"field": "title",
"query": "數據讀寫",
"size": 10
}
}
得到的结果如下:
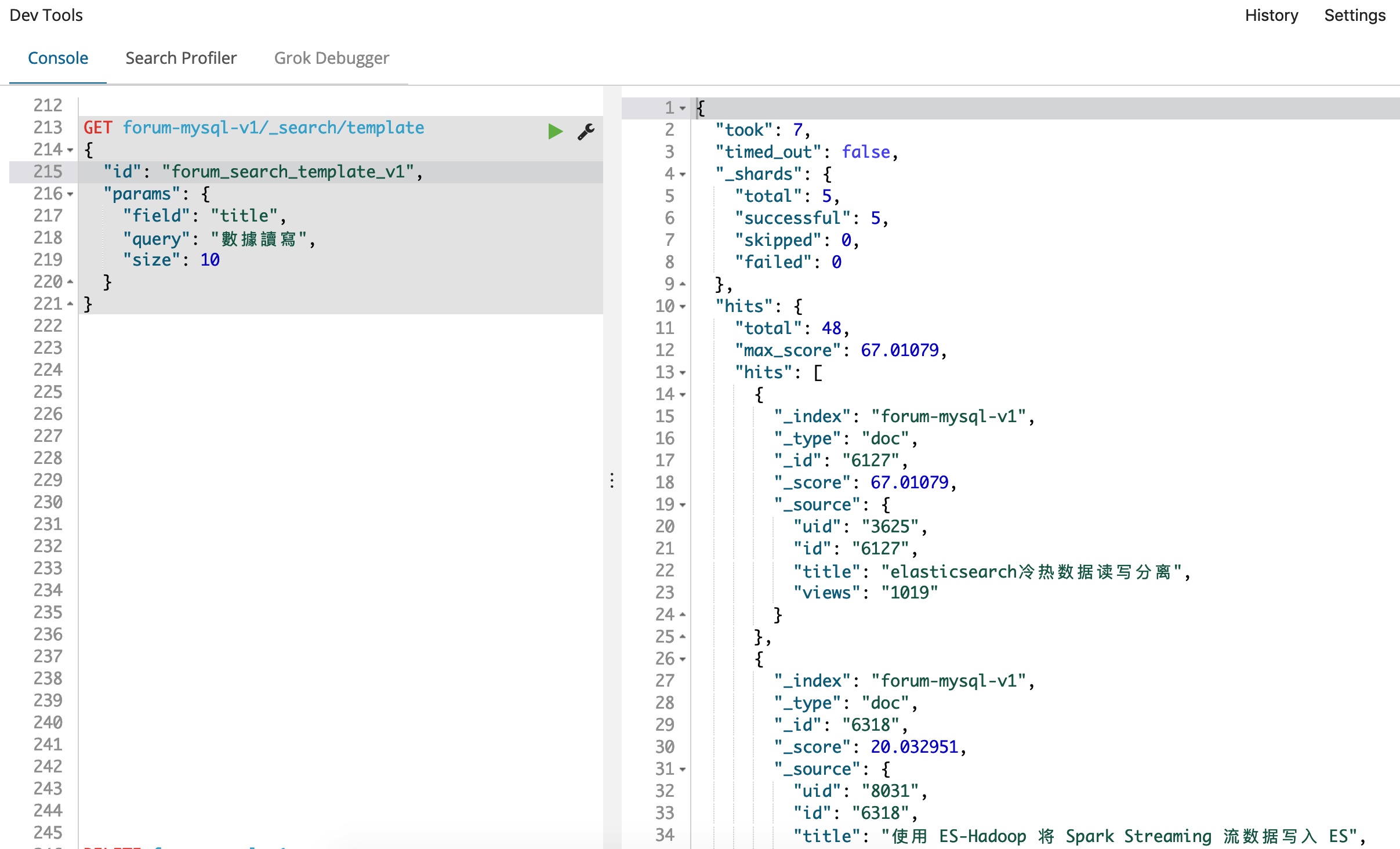
这次我们可以看到,我们命中了更多的结果,并且返回的第一条数据,和我们的查询条件关联度非常好,尽管查询条件用的是繁体,而内容却是简体,但是都完美无误的找到了。反过来,如果内容是繁体的,但是很相关,我们就算用简体字的查询条件,现在应该也能找出来了。
最后再回到我们的前台界面,结合本章开头的任务要求,我们尝试搜索 學習, 发现已经准确无误的找到所需的内容。